오늘은 이전 포스팅에 이어, 영화 리뷰를 크롤링하고 워드 클라우드를 만들 것이다.
2021.06.07 - [분류 전체보기] - Python으로 크롤링(Crawling)하기
크롤링할 사이트는 '로튼 토마토(Rotten Tomatoes)'이다. 로튼 토마토는 영화에 대한 소식, 비평, 정보 등을 제공하고, Tomatometer 점수를 사용하여 긍정적인 리뷰(fresh)가 많은지, 부정적인 리뷰(rotten)가 많은 지 구분한다.

이제 영화 리뷰를 크롤링해보자!
1. Review 크롤링
리뷰 텍스트가 어떤 태그에 있는지 알아보기 위해, 영화 '크루엘라(Cruella)'의 리뷰 페이지를 확인했다.

[그림 2]를 보면, class가 "the_review"인 <div> 태그에 영화 리뷰가 있다는 것을 알 수 있다.
따라서 이 페이지의 리뷰를 모두 크롤링하려면 아래와 같이 코드를 작성하면 된다. reviews에는 리뷰가 있는 태그들이 리스트 형태로 저장될 것이다.
import requests
from bs4 import BeautifulSoup
url = 'https://www.rottentomatoes.com/m/cruella/reviews'
resp = requests.get(url)
soup = BeautifulSoup(resp.text)
reviews = soup.select("div.the_review")
reviews
[<div class="the_review" data-qa="review-text">
The sheer volume of outfits worn by Stone and the rest of the cast, is matched only by the level of detail on each.
</div>,
<div class="the_review" data-qa="review-text">
The result is the complete mangling of one of the greatest Disney villains of all time.
</div>,
<div class="the_review" data-qa="review-text">
Stylish and entertaining, but could probably stand to lose 15 minutes.
</div>,
...(생략) ,
<div class="the_review" data-qa="review-text">
There's so much to love here! I appreciated seeing Estella's (Cruella's) creativity shine and her bravery in facing hardship.
</div>]
[그림 2]를 다시 확인하자. 리뷰 우측 상단에 'Page 1 of 18' 문구가 있다. 지금 크롤링 한 내용은 전체 리뷰의 18분의 1 밖에 안되고, 현재 사용하는 URL(https://www.rottentomatoes.com/m/cruella/reviews)에서는 전체 리뷰를 가져오는데 한계가 있다는 것이다.
'Page 1 of 18' 우측의 화살표를 클릭하여 다음 페이지로 넘어가고, URL를 확인하면 아래와 같다.
https://www.rottentomatoes.com/m/cruella/reviews?type=&sort=&page=2
type는 리뷰어의 타입을 의미하여, 각 리뷰어의 리뷰 페이지를 보려면 type= 뒤에 아래 값을 입력하면 된다.
- All Critics: 디폴트 값
- Top Critics: top_critics
- All Audience: user
- Verified Audience: verified_audience
page는 리뷰 페이지 번호를 의미한다.
위 URL 중 cruella는 영화 제목으로 다른 영화 제목을 입력하면 해당 영화에 관련된 리뷰를 확인할 수 있다.
우선 크루엘라에 대한 전체 비평가(All Critics)의 리뷰를 크롤링하겠다.
def get_movie_reviews(movie_name):
url_template = 'https://www.rottentomatoes.com/m/{}/reviews?type=&sort=&page={}'
page = 1
review_text = ''
while True:
url = url_template.format(movie_name, page)
resp = requests.get(url)
soup = BeautifulSoup(resp.text)
if soup.select_one("div.the_review") == None:
break
for review in soup.select('div.the_review'):
review_text += review.get_text()
page += 1
return review_text
영화 제목을 입력으로 받고, 전체 비평가의 리뷰를 크롤링하여 review_text로 반환하는 함수이다.
반복문으로 리뷰 페이지를 넘기며, 리뷰 내용을 review_text에 담고, 페이지에 리뷰가 없으면 반복문을 중단한다.
만든 함수를 실행해보자.
review_text = get_movie_reviews('cruella')
print(review_text)
The sheer volume of outfits worn by Stone and the rest of the cast, is matched only by the level of detail on each.
The result is the complete mangling of one of the greatest Disney villains of all time.
Stylish and entertaining, but could probably stand to lose 15 minutes.
These clothes are the boldest element of a movie that otherwise wears its supposed punk-rock influences like a kid discovering Hot Topic for the first time.
It would have been deadly for a movie as fashion-centred as this to not deliver on costume design, but thankfully, the outfits worn by both Emmas are, as they say, something else.
...(생략)
2. Word Cloud 만들기
크롤링한 리뷰로 간단한 워드 클라우드를 만들면 [그림 3]처럼 만들어진다.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wc = WordCloud(max_font_size=200, background_color='white', width=800, height=800)
wc.generate(review_text)
plt.figure(figsize=(10, 10))
plt.imshow(wc)
plt.tight_layout(pad=0)
plt.axis('off')
plt.show()
3. 심화 버전
좀 심심한 것 같아서, 로튼 토마토의 특징인 신선한 토마토와 썩은 토마토 그림으로 만들어보려 한다. 신선한 토마토에는 긍정적인 리뷰를, 썩은 토마토에는 부정적인 리뷰를 넣을 것이다.
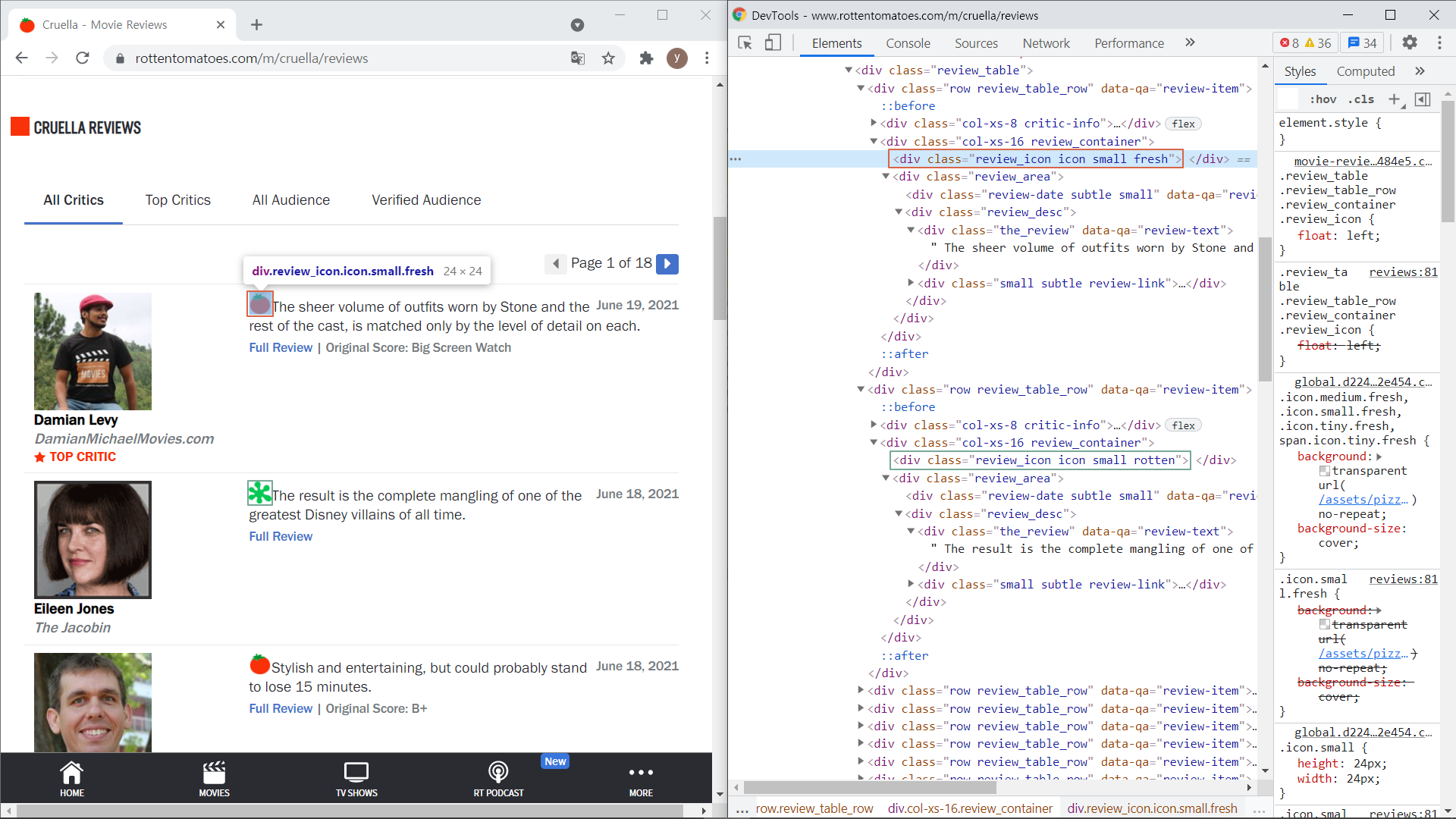
긍정적인 리뷰인지, 부정적인 리뷰인지는 [그림 4]처럼 리뷰에 있는 토마토 그림을 보면 된다. 긍정적인 리뷰는 class 속성이 'review_icon small fresh'이고, 부정적인 리뷰는 class 속성이 'review_icon small rotten'이다. 각각의 리뷰 아이콘과 리뷰 텍스트는 class가 'col-xs-16 review_container'인 <div> 태그 하위에 있다.
def get_movie_reviews2(movie_name):
url_template = 'https://www.rottentomatoes.com/m/{}/reviews?type=&sort=&page={}'
page = 1
fresh_review_text = ''
rotten_review_text = ''
while True:
url = url_template.format(movie_name, page)
resp = requests.get(url)
soup = BeautifulSoup(resp.text)
if soup.select_one("div.the_review") == None:
break
for review_container in soup.select('div[class="col-xs-16 review_container"]'):
tomato = review_container.select_one('div')['class']
review = review_container.select_one('div.the_review')
if tomato[-1] == 'fresh':
fresh_review_text += review.get_text()
elif tomato[-1] == 'rotten':
rotten_review_text += review.get_text()
else:
print('other tomato!!!')
page += 1
return fresh_review_text, rotten_review_text
fresh_review_text, rotten_review_text = get_movie_reviews2('cruella')
영화 제목을 입력으로 받고, 전체 비평가의 리뷰를 크롤링하여 fresh_review_text와 rotten_review_text로 반환하는 함수이다. 리뷰 컨테이너를 먼저 가져와서 바로 하위의 <div> 태그(토마토 아이콘을 의미)의 class 명으로 fresh review인지, rotten review인지를 구분한다. fresh review이면 리뷰 내용을 fresh_review_text에 담고, rotten review이면 리뷰 내용을 rotten_review_text에 담는다.
from PIL import Image
import numpy as np
from wordcloud import ImageColorGenerator
mask_fresh = np.array(Image.open("tomato.png"))
mask_rotten = np.array(Image.open("rotten.png"))
color_fresh = ImageColorGenerator(mask_fresh)
color_rotten = ImageColorGenerator(mask_rotten)
wc1 = WordCloud(max_font_size=200, background_color='white', width=800, height=800, mask=mask_fresh, color_func=color_fresh)
wc1.generate(fresh_review_text)
wc2 = WordCloud(max_font_size=200, background_color='white', width=800, height=800, mask=mask_rotten, color_func=color_rotten)
wc2.generate(rotten_review_text)
plt.figure(figsize=(20, 10))
plt.subplot(121)
plt.imshow(wc1)
plt.tight_layout(pad=0)
plt.axis('off')
plt.subplot(122)
plt.imshow(wc2)
plt.tight_layout(pad=0)
plt.axis('off')
plt.show()
워드 클라우드 결과가 그다지 의미 있진 않은 것 같지만, 이런 것을 할 수 있다 예시이니까 넘어가주길 바란다.

'Python' 카테고리의 다른 글
| 알쓸코드 - 데이터 분석 (1) | 2023.11.04 |
|---|---|
| [Python] 리스트 컴프리헨션(list comprehension) (0) | 2021.10.12 |
| Python으로 잔여백신 상태 확인하기 (5) | 2021.07.25 |
| Python으로 크롤링(Crawling)하기 (2) | 2021.06.07 |
| 웹 기본 지식 (2) | 2021.05.29 |



댓글