모델의 속도를 높일 수 있는 최적화 알고리즘(Optimization Algorithms)을 알아보자.
1. Mini-Batch
지금까지 우리는 전체 데이터 X (
Batch gradient descent는 m이 커질수록 gradient를 계산이 느려지는 문제가 있다.
전체 데이터를 mini-batch로 나눈뒤 gradient를 계산하는 Mini-Batch gradient descent 를 사용하여 gradient 계산 속도를 높일 수 있다.
ex) m=5,000,000인 데이터 셋을 mini-batch size=1,000으로 나누는 경우,
의 mini-batch로 나뉠 것이다.
Mini-Batch gradient descent는 각 mini-batch t(
하나의 mini-batch에 대한 gradient descent를 1 epoch이라고 한다. 5,000개의 mini-batch의 경우 1 iteration에서 5,000 epoch을 진행한다.

하나의 데이터
Stochastic gradient descent은 noise가 많이 발생하고, 벡터화를 통한 빠른 계산속도를 잃는다는 단점이 있다.
적당한 mini-batch size를 찾아 Mini-Batch gradient descent를 수행하는 것이 계산 속도를 높일 수 있다.
적당한 mini-batch size를 찾는 방법은 다음과 같다.
- training set이 작다면, Batch gradient descent를 사용하라. (ex. m ≤ 2,000)
- mini-batch size는 2의 지수값으로 설정하라. (ex. 64, 126, 256, 512)
- mini-batch
2. Momentum / RMSprop / Adam
Momentum, RMSprop, Adam에 사용되는 개념인 Exponentially weighted average를 알아보자.
1년간 런던 날씨를 수집하여 차트로 나타내면 아래와 같이 분포되어 있다.
이전 날씨 값의 가중 평균을 더하여, 런던 날씨의 trend를 알 수 있다.
Exponentially weighted average 식은 아래와 같다.
예전 날씨는 기하급수적으로 적게 반영되어,
Exponentially weighted average의 초반부는
Bias correction으로 초반부의 값을 더 정확하게 계산할 수 있다.
2.1 Momentum
Momentum은 Gradient Descent에 Exponentially weighted average를 적용한 알고리즘이다.
Mini-Batch Gradient Descent의 Cost 최적화 과정에 있는 진동폭을 Momentum 사용하여 줄일 수 있다.
2.2 RMSprop
RMSprop는 root mean square propagation의 약자로 제곱평균제곱근(root mean square)이 작은 방향으로 업데이트한다.
(rms가 크면 진동폭이 크고, rms가 작으면 진동폭이 작음을 의미하기 때문에 진동폭이 작은 방향으로 업데이트하여 cost 최적화 속도를 높일 수 있다.)
2.3 Adam
Adam은 Momentum과 RMSprop를 결합한 알고리즘이다.

3. Learning rate decay
Mini-Batch Gradient Descent의 경우 최적값 주변을 맴돌면서 수렴하지 않을 수 있다.
Learning rate
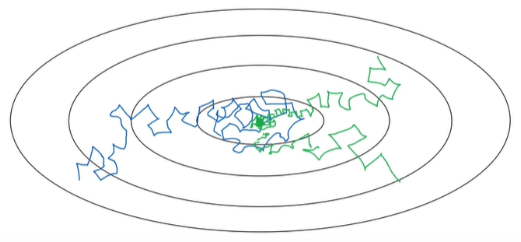
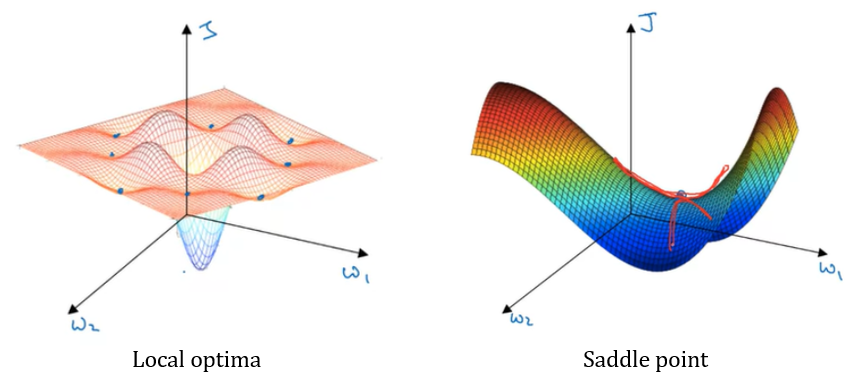
최적화 알고리즘을 사용하다 보면 local optima에 수렴할 것 같지만, 실제 Neural Network에서 local optima에 수렴할 확률은 매우 낮다. 기울기가 0인 지점은 대부분 saddle point이다.
'Deep Learning' 카테고리의 다른 글
| 2.3 Hyperparameter Tuning, Batch Normalization (0) | 2023.03.27 |
|---|---|
| 2.1 Practical Aspects of Deep Learning (0) | 2023.02.28 |
| 1.3 Deep Neural Networks (0) | 2023.02.21 |
| 1.2 Shallow Neural Networks (0) | 2023.02.14 |
| 1.1 Neural Networks Basics (1) | 2023.02.07 |




댓글